חיפוש ואחזור מידע Big Data
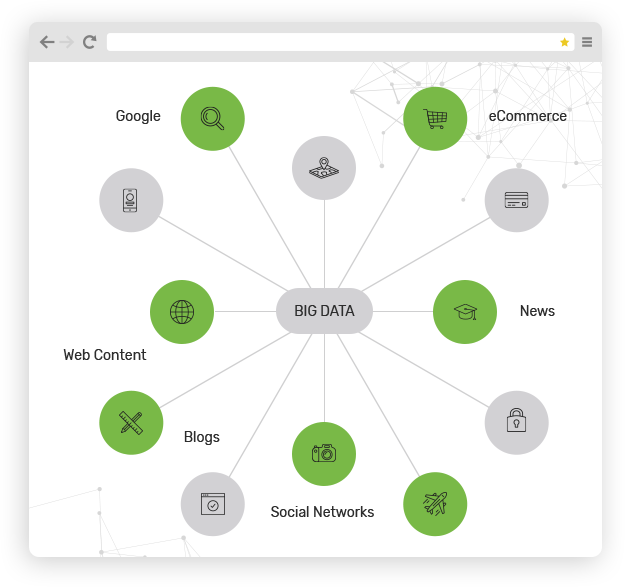
התפוצצות המידע
אריק שמידט, יו"ר גוגל, אמר ב-2010 שכל יומיים אנחנו מייצרים כמות מידע זהה לזו שייצרנו מראשית הציוויליזציה ועד 2003, אז זה נשמע כמדע בדיוני אולם המציאות גוברת על הדמיון. על פי נתוני מחקר שפורסם נפח המידע גדל והולך במימדים עצומים. על פי המחקר ההערכה שעד 2020 עבור כל אדם על כדור הארץ יווצרו 1.7MB של נתונים בכל שנייה.
המושג ביג דאטה (Big Data) הפך בשנים האחרונות לבאזז החדש.
נְתוּנֵי עָתֵק, Big Data הם מאגרי מידע הכוללים נתונים מבוזרים, עשירים, מגוונים, כוללים מדיה עשירה, מגיעים משלל ערוצים ומקורות, בכמויות גדולות, מתעדכנים במהירות, ובפורמט משתנה.
הטכנולוגיה הנדרשת כדי להתמודד עם כמויות גדולות מאי פעם של נתונים בפורמט קבוע או משתנה עם טקסט חופשי כבר עומדת בהישג ידם של ארגונים ועסקים אולם התפוצצות המידע הופכת את אחזור הנתונים לצורך קבלת החלטות למשימה מורכבת.
חיפוש חכם על ידי שילוב מנוע החיפוש Solr עם מערכת ניהול הנתונים SignatureIT Data Management
בין פלטפורמת SignatureIT Data Management לאחזור וניהול נתונים לבין מנוע החיפוש Solr קיים ממשק הנמצא בשימוש במגוון רחב של יישומים, אפליקציות ומערכות. המוצרים מקושרים לעומקם, ולמעשה מהווים מוצר ופתרון אחד שלם בפרויקטים לחיפוש ואחזור מידע.
מנוע ה-Solr מאנדקס את הנתונים המנוהלים במערכת כאשר האחרונה מספקת מסכי ניהול ושליטה במודל הנתונים, בשיטת האינדוקס, היקפו ותזמונו. כך מתקבלת שכבה דינאמית התואמת את צרכי הארגון ויכולה להתאים את עצמה בקלות לצרכים המשתנים בעתיד.
השילוב מאפשר ישום לוגיקה עסקית לחיפוש, ליצור חוקים "צפים" ליצירת קשרים בעלי משמעות בין פריטים ויישויות מידע, חיפוש ואחזור מידע וללא תלות בתוכן המאוחזר עצמו.
ניתן ליצר קשרים, לבטלם, לתחקרם ולהגדיר את התנהגותם כתלות בתהליך או צורך עסקי דבר המאפשר להרחיב ולהעשיר את תוצאות החיפוש ללא תלות בתוכן.
ניתן ליצור ישות שלא קיימת בתוכן המאוחזר, לקבוע את מאפייניה ולהגדיר את מקורות המידע לכל מאפיין. על פי מקור מידע ומהימנותו ניתן להגדיר את ה-Rating לאותו המאפיין דבר שיתבטא בתוצאות החיפוש.
אנו מתמחים ביישום והטמעה של פתרונות חיפוש
אנו משלבים דיסציפלינות של ארגון מידע ופיתוח טקסונומיה, התמחות באפיון חווית חיפוש עבור המשתמש עם ניסיון רב ביישום טכנולוגיות לחיפוש וארגון מידע מבוססים על מנוע החיפוש Solr ומוצרים משלימים ליישומי שפה וניתוח טקסט על מאגרי מידע מבוזרים, עצומים בגודלם, משתנים וממקורות מגוונים.
Solr הוא מנוע חיפוש אחוד מתקדם, מהנפוצים בעולם בקוד פתוח ובארכיטקטורת REST ומבוסס על Lucene. המנוע מאנדקס ומטייב תכנים אשר נגישים ב-API ומגיש תוצאות חיפוש במהירות גבוהה מאוד. המנוע כולל תכונות עשירות של חיפוש כגון Analyzers לניתוח שפות, Highlights להדגשת תוצאות חיפוש, Suggestions להשלמה אוטומטית ותומך בפורמטים נרחבים של מסמכים.
המנוע תומך בחיפוש מופץ (Distributed Search), אינדוקס בזמן אמת משוכפל (Index Replication) ובנוי בצורה סקלבילית (Scalability) לעמוד בנפחים ועומסים גבוהים (Fault Tolerance), בשרידות וזמינות (Cluster) גבוהה.
-
מיישמים טקסונומיה ארגונית לארגון המידע וניווט

-
מייצרים חוקים עסקיים ויוצרים קשרים בעלי משמעות בין פריטי מידע

-
מנגישים את המידע למשתמש באמצעות ממשק חיפוש נוח, יעיל וחוויתי

הנתונים הם הכוח
איל וולדמן, נשיא ומנכ"ל מלאנוקס אמר "כיום יותר ויותר אנשים מבינים כי המשאב הכי חשוב ויקר בעולם הוא נתונים", "כשמסתכלים על הנתונים צריך להבין מה לעשות איתם - נתונים הם הכוח".
כדי לנצל את הנתונים לקבלת החלטות עסקיות או לספק את המידע הדרוש למשתמש במקום הנכון ובזמן הנכון יש צורך לארגן את המידע כך שיקל על המשתמשים לאתרו.
הטכנולוגיה הנדרשת כדי להתמודד עם כמויות גדולות מאי פעם של נתונים בפורמט קבוע או משתנה עם טקסט חופשי כבר עומדת בהישג ידם של ארגונים ועסקים אולם התפוצצות המידע הופכת את אחזור הנתונים לצורך קבלת החלטות למשימה מורכבת.
שילוב שיטות שונות לארגון ואחזור המידע יסייעו לספק למשתמשים מתוך הארגון ומחוצה לו לקבל את המידע הדרוש להם בזמן ובמקום הנכון.